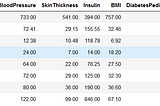
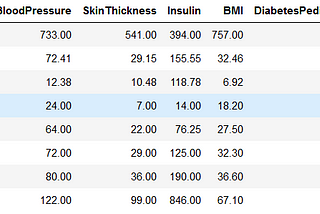
Shonit GangolyClassification on Diabetes Data setUsing Classification models on Pima Indians Diabetes Data set16 min read·May 1, 2021----
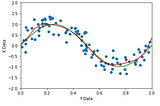
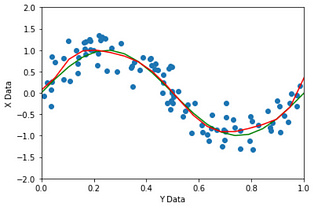
Shonit GangolyOver fitting in Polynomial RegressionThe goal is to understand the concept of over fitting by using polynomial regression.7 min read·Apr 7, 2021----
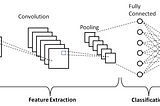
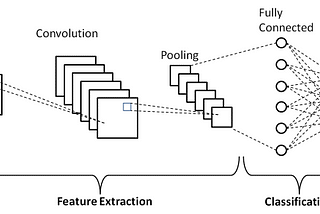
Shonit GangolyCNN on CIFAR10 Data set using PyTorchThe goal is to apply a Convolutional Neural Net Model on the CIFAR10 image data set and test the accuracy of the model on the basis of…11 min read·Mar 29, 2021--1--1
Shonit GangolyTitanic Kaggle ChallengeMy contribution towards the Titanic Challenge on Kaggle.8 min read·Feb 23, 2021----